Why does buy-side research take 15 to 20 hours per engagement?
The data exists in public filings, but consolidating it into a usable buyer list is a manual research project that runs every time a banker takes on a new mandate. Existing databases report self-declared interest rather than actual deployment behavior, and the time pressure on a sell-side process compounds the problem.
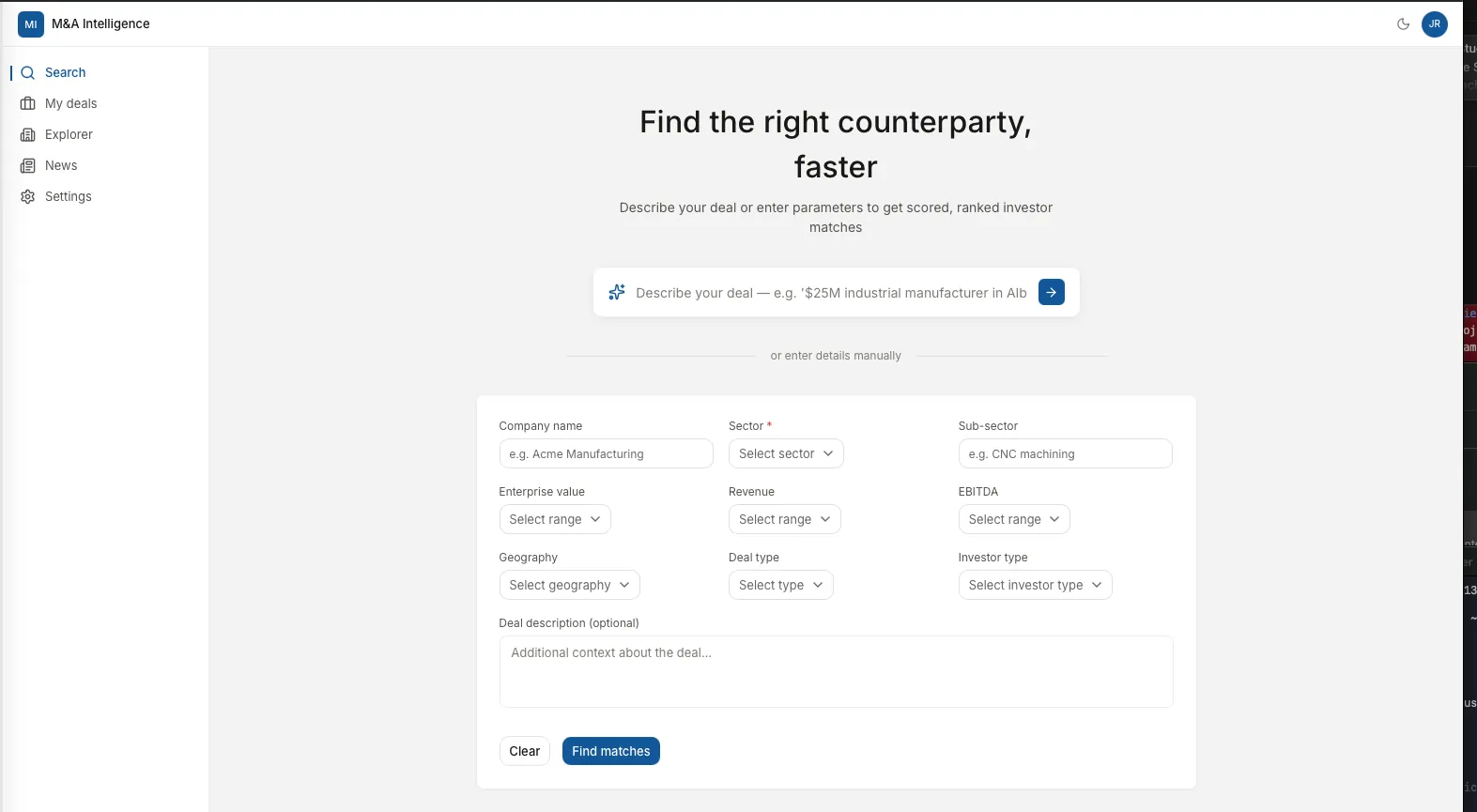
Investment bankers running sell-side M&A engagements face a persistent operational bottleneck: identifying which buy-side firms (private equity funds, credit funds, family offices, strategic acquirers) are actively deploying capital in a specific sector, size range, and geography. The traditional approach relies on personal relationships, outdated spreadsheets, and expensive subscription databases that report self-declared interest rather than actual capital deployment behavior.
A banker placing a $25M industrials company in the US Midwest might spend 15 to 20 hours manually researching potential acquirers, cross-referencing databases, and cold-calling contacts. The output is a buyer list that misses active funds and includes firms that have shifted their mandates since the data was last updated. That research happens again on the next engagement, and the engagement after that, with no compounding learning.
The core insight is that every time an investment firm deploys capital, it leaves a public paper trail. SEC Form D filings, Form ADV registrations, 13F institutional holdings, BDC quarterly reports, law firm deal tombstones, and PE portfolio announcements are all public records that reveal actual capital behavior. The opportunity is to scrape, cross-reference, deduplicate, and score that data systematically, so that every new engagement starts from a continuously updated database rather than a blank spreadsheet.
Our approach: a unified entity database with a fast, deterministic scorer on top
Public M&A data is messy in specific, predictable ways. The architecture is built around solving each one explicitly, not around hiding the mess behind a single LLM prompt.
Raw data is quarantined before it touches the main database. Every web scraper writes new records to a holding area, never directly to the production database. The data only moves to production after it has been cleaned, deduplicated, and verified. A bug in any one scraper cannot corrupt the rest of the system; the worst case is a bad batch that gets thrown out before it ever reaches the firms an analyst actually sees.
Three passes to recognize the same firm under different names. Raw data from public filings is messy; the same firm name might appear three different ways across documents. The system cleans this up in three passes, starting with the most confident matches and working down to harder cases. Exact-name matches run first. Then a fuzzy text-comparison pass catches close-but-not-identical spellings. Finally, a meaning-based pass catches the cases where the text is different but the firm is the same. (Technically: deterministic matching, fuzzy matching with RapidFuzz at a 97% threshold, then 768-dimensional vector matching in pgvector.)
Speed matters, and AI is too slow for some calculations. Scoring 200 candidate firms in under 50 milliseconds requires plain code, not AI calls. The system uses AI for tasks that need real understanding of language (writing descriptions, classifying industries, parsing responses) and uses code for tasks that need speed and consistent results (filtering, scoring, ranking). Mixing the two would make scoring slow and unpredictable.
Free sources first, paid sources last. Looking up a firm's website costs different amounts depending on where you look. The system tries the free options first (a Google directory and a domain-guessing trick), then a mid-tier paid source for what remains, and only hits the most expensive paid search for the leftovers it could not solve any other way. This single change cut website lookups from about $20 a day to about $1 to $2 a day, a roughly 90 percent reduction.
For a plain-language view of how the searchable database underpins natural-language queries, see our guide to how RAG searches your own data instead of guessing.
Inside the 27-stage pipeline
The pipeline has 27 separate steps that run in sequence. Each step does one specific job (reading new filings, recognizing the same firm under different names, looking up websites, classifying industries, finding the right people, and so on). Steps can be tested in isolation, paused, restarted from any point, or skipped if not needed. A test run on three sample records costs $0.15 and validates the entire workflow before committing to a full batch.
14 data sources through purpose-built scrapers
Four SEC scrapers handle the structured filings: Form D for fund raises, Form ADV for investment adviser details (AUM, investment style, fund relationships), Form 13F for institutional equity positions, and BDC quarterly reports for private credit loan portfolios. Each scraper handles the specific XML or HTML format of its filing type.
Five web scrapers extract deal history from law firm tombstone pages across 67 configured firms, press release feeds with LLM-powered entity extraction, and PE portfolio pages. A dedicated team-page scraper discovers personnel from investment firm websites using structural HTML parsing, with an LLM fallback for non-standard layouts.
Five third-party enrichment integrations cross-reference each entity: GLEIF for global entity identifiers and parent-child hierarchies, FINRA CRD numbers via Form ADV bulk data, OpenCorporates for incorporation data, Google Knowledge Graph for website discovery, and a commercial provider for LinkedIn company profiles.
Recognizing the same firm under different names
Raw SEC filings include thousands of firm names with inconsistent formatting, abbreviations, and fund vehicle variations. "Blackstone Capital Partners VII, L.P.," "BLACKSTONE CAPITAL PARTNERS VII LP," and "BCP VII Co-Invest" might all refer to the same parent firm. The system runs three matching passes in order, starting with the most confident: exact name matches, then close-but-not-identical text matches, then meaning-based matches that catch cases where the spelling differs but the firm is the same.
After matching, a second tool groups the matched names into parent firms. Many investment firms run multiple funds (Fund I, Fund II, Fund III, plus side vehicles, offshore variants, and feeder funds) and all of those need to roll up under one canonical parent so an analyst sees "Blackstone" once instead of twelve times. The grouper looks at fund-numbering patterns, "a series of" references in legal documents, shared identifiers across regulatory databases, and shared websites.
The result: approximately 8,000 raw entries from SEC filings collapse into roughly 3,190 deduplicated parent firms, with 5,000+ child fund vehicles correctly grouped beneath them. Four different ID systems (SEC, GLEIF, FINRA, OpenCorporates) cross-reference each firm so that data from any of those sources can be matched up reliably.
Filling in the details and checking the work
Once each firm has a stable identity, the next nine steps fill in the operating details. AI reads the firm's website and writes a short standardized description. The system classifies the firm into one of 27 industries (with about 500 alias mappings to handle ambiguous cases). It tags the firm's role on each deal it has done (acquirer, lender, growth investor). It analyzes public holdings data to figure out where the firm is concentrated. It pulls investment criteria from regulatory brochures.
The next nine steps build the people side. The system finds investment professionals on team pages, deduplicates them across data sources, classifies their seniority (Partner, Managing Director, VP), checks LinkedIn to confirm they still work there, and builds verified email addresses for outreach.
The final step is an automated quality check. An AI reads each enriched firm record and verifies the website is right, the description matches the firm, the firm type is correct, and the deal roles are accurate. Firms that pass advance into the production database. Firms that fail are flagged for human review. This automated check handles about 90 percent of records; the remaining 10 percent need a human to look at them.
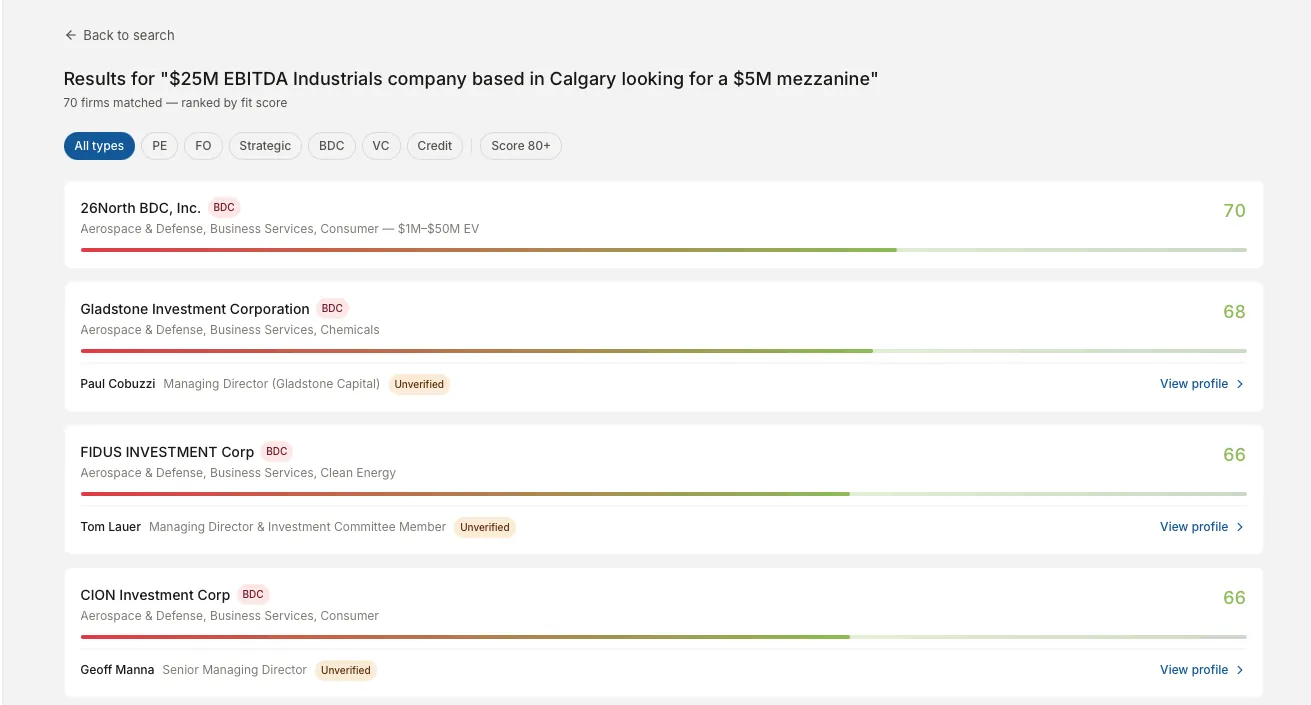
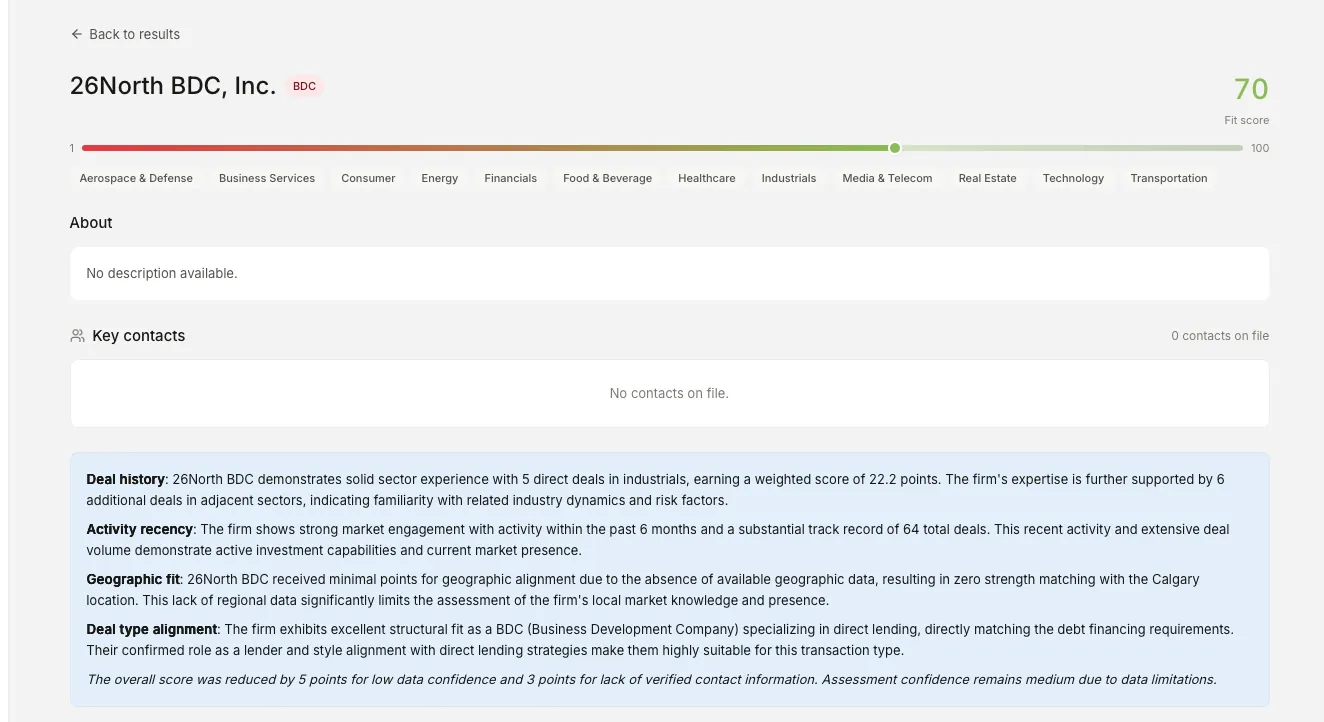
The scoring engine and the explanation built on top
A banker types in deal parameters either as structured fields or in plain English ("$25M industrials company in Alberta, recurring revenue, PE buyer"). The system reads the parameters, narrows the database down to a few hundred to a few thousand candidates that meet the basic criteria, then scores each candidate on four factors.
Each factor is worth 25 points, for a total score from 1 to 100. Deal history measures how many similar deals the firm has actually done, weighted by their role on each one. Activity recency measures how recently the firm has been deploying capital. Geographic fit measures whether the firm is active in the right region. Deal type alignment measures whether the firm typically buys companies of this size, structure, and stage.
All scoring finishes in under 50 milliseconds for 200 firms because it runs as plain code rather than AI calls. The plain-English explanation of why each firm scored where it did is generated on-demand, only when the banker clicks into a specific firm. This keeps AI spend predictable and small.
The four-component scorer is a working baseline, not the production target. It establishes the core architectural pattern (deterministic scoring on top of clean entity data, fast enough to rank thousands of candidates in milliseconds) and proves that the underlying database can drive accurate buyer matching.
The production roadmap is a fine-tuned model trained on historical deal outcomes: which firms actually closed which kinds of deals, weighted by how recent each deal was and by mandate signals confirmed in outreach. A model trained on this data captures the patterns a senior banker uses intuitively, like "this firm always passes on industrials below $50M" or "that firm has been quietly entering renewables," without anyone having to encode those rules by hand.
The infrastructure for this upgrade is already in place. Every deal observation, mandate confirmation, and scoring outcome is logged in a structured format suitable for fine-tuning. The four-component scorer stays as the fast deterministic layer. The fine-tuned model adds a learned weighting layer on top, combining the speed and predictability of code with the pattern recognition of a model trained on the firm's own deal history.
Automated outreach with strict guardrails
The platform sends automated emails to investment professionals asking them to confirm their current investment criteria. Each contact gets up to three emails: an initial outreach, a follow-up at day 15, and a final close at day 30. Every email shows the firm's current profile in the database and asks for a one-word confirmation or corrections.
Several rules run before any email leaves the queue, so the platform never sends a poorly-targeted message. Mega-funds (over $50 billion in assets), advisory firms, and non-investment entities are skipped entirely. Firms without enough data on file (sector and either deal size or geography) are skipped. No more than three people at any one firm get contacted. Only senior investment titles (Partner, Managing Director, Director, VP, CEO, Portfolio Manager) qualify. Names are cleaned up (professional designations stripped, ALL-CAPS converted) before any message goes out.
When responses come in, a small AI sorts them automatically into categories (confirmed mandate, referral, not interested, out of office, bounce) and pulls structured details from free-text replies. Confirmed mandates are saved at the person level, so the system knows the specific investment criteria of individual professionals, not just generic firm descriptions. Every outreach action is logged for audit, and the whole outbound flow runs through hard-coded rules rather than relying on an AI's judgment about whether to send.
What did this enable?
15 to 20 hours of manual research per engagement collapsed into a database query that returns scored, ranked candidates in milliseconds. The full pipeline runs end-to-end in 30 to 45 minutes for a 100-firm production batch, validates end-to-end for $0.15 in test mode, and stores 8,983 investment transactions and 12,175 indexed professionals as a continuously refreshed asset.
3,190
Deduplicated parent firms from 8,000+ raw entities
12,175
Investment professionals indexed with role classification
8,983
Investment transactions tracked across sources
< 50ms
Scoring engine response time for 200 candidates
14
Distinct data sources integrated through custom scrapers
27
Sequential pipeline stages, fully automated
Beyond the scale numbers, the bigger shift is that buy-side research stops being a per-engagement project. The database refreshes continuously in the background. Every new engagement starts from up-to-date data. The cheaper-source-first lookup pattern keeps daily operating costs at $1 to $2 per day rather than the $20 a brute-force approach would run, and the automated quality check handles 90 percent of records without human attention. 6,174 verified email addresses sit pre-validated and ready to use.
Could this work for your business?
The pattern is manual research workflows on document-heavy public data with compliance-sensitive outputs. If your team currently spends hours per engagement consolidating public records, scoring or ranking entities against custom criteria, and producing outbound communication that needs an audit trail, this architecture maps directly to your business.
It applies to insurance brokerages running carrier sourcing across regulatory filings, claim histories, and rate filings. It applies to legal firms doing litigation research across PACER filings and prior matter databases. It applies to real estate buyer intelligence consolidating public records, transaction histories, and entity ownership across multi-LLC structures. It applies to government contracting target lists across SAM.gov, USAspending, and DSBS profiles. It applies to executive search firms scoring candidates against role criteria across LinkedIn, GitHub, and conference participation.
What changes per industry is the data source mix, the entity resolution rules (every domain has its own naming conventions and identifier systems), and the scoring formula. The shape stays the same: staging-first ingestion, multi-pass entity resolution, separation of fast deterministic scoring from contextual LLM enrichment, cost-tiered API waterfalls, and an autonomous quality review gate before anything reaches the production dataset.
Tech stack
Backend
Database & vectors
AI & embeddings
Web scraping & enrichment
Frontend
Frequently asked questions
How long does an M&A deal sourcing platform implementation take?
A typical buildout is ten to fourteen weeks. Custom scrapers for the data sources you care about take longest, since each filing format and law firm tombstone page has its own structure. Entity resolution rules, scoring weights, and outreach templates are configured against your firm's specific deal book in the second half of the engagement.
What is entity resolution and why does it matter for M&A data?
Entity resolution is the process of recognizing that "Blackstone Capital Partners VII, L.P.," "BLACKSTONE CAPITAL PARTNERS VII LP," and "BCP VII Co-Invest" all refer to the same parent firm. Without it, public M&A data is unusable: the same firm appears as five different entities, scoring is broken, and contact lists are duplicated. The platform runs three resolution passes (deterministic, fuzzy, embedding-based) plus a seven-pass fund grouper to consolidate variants into canonical parent firms.
Why is the scoring engine separate from the AI layer?
Scoring 200 candidate firms in under 50 milliseconds requires deterministic Python math, not LLM calls. The platform uses LLMs for tasks that need contextual understanding (description generation, sector classification, mandate extraction, response parsing) and uses pure code for tasks that need speed and reproducibility (scoring, filtering, ranking). Mixing the two would make the scoring layer slow and non-deterministic.
How does the platform avoid spamming investment professionals?
Pre-send filters enforce strict quality gates before any email leaves the queue: a blocklist for mega-funds and non-investment entities, a minimum profile threshold requiring confirmed sector and deal size data, a per-firm contact cap of three professionals maximum, a role filter limiting outreach to senior investment titles only, and name validation that strips professional designations and corrects formatting. The result is a deliberately small, high-quality outreach footprint.
Can this approach work for verticals beyond M&A?
Yes. The pattern is manual research workflows on document-heavy public data with compliance-sensitive outputs. The same architecture maps to insurance carrier sourcing, real estate buyer intelligence, government contracting target lists, and regulated outreach in any vertical where the data exists in public filings but takes hours of manual work to consolidate.
Related case studies
Internal Tooling
One platform replaced seven subscriptions
A solo-operator platform that unifies lead capture, scheduling, customer records, files, and analytics into one integrated system, with every workflow connected through a single customer record.
Read →Venture Capital
Centralized Intelligence Platform for Venture Capital
A multi-agent platform monitoring 138 VC firms and producing institutional-quality investment theses in 5 to 7 minutes.
Read →Internal Tooling
Building a Private Knowledge Graph That Actually Answers Questions
A local-first memory system that ingests 1,400+ documents and answers questions with citations in under a second.
Read →