The problem: AI does not know your business.
Imagine you hire a brilliant consultant. This person has read millions of books, research papers, and articles. Ask them about macroeconomics, supply chain theory, or marketing frameworks, and they will give you a sharp, detailed answer. They are genuinely impressive.
Now ask them: "What is our company's refund policy for damaged goods?" They have no idea. They have never seen your internal documents, your employee handbook, or your customer service playbook. But here is the problem: they will still try to answer. They will piece together something that sounds plausible based on what they know about refund policies in general. It might be close. It might be completely wrong. Either way, they are guessing.
This is exactly what happens when you ask a general-purpose AI about your business. It does not have access to your files, your policies, or your data. When forced to answer anyway, it generates something that sounds reasonable but may have nothing to do with reality. Sometimes it gets lucky. Often it does not. And the confident tone makes it hard to tell the difference.
What RAG actually does.
RAG stands for Retrieval-Augmented Generation. The name is technical, but the concept is simple. Instead of forcing the AI to answer every question from memory, RAG gives it a searchable library of your company's actual documents. Before the AI responds to any question, it searches your files first, finds the relevant sections, reads them, and then writes an answer based on what it found. It includes source citations so you can verify the answer yourself.
No guessing. No making things up. The AI becomes a research assistant with access to your entire knowledge base. It can pull from employee handbooks, product documentation, internal wikis, sales playbooks, or any other documents you give it. When it answers a question, it tells you exactly which document and which section it used. If the information is not in the documents, a well-built RAG system will say so instead of fabricating an answer.
This is the difference between a chatbot that sounds smart and a tool that is actually useful. RAG turns AI from a general-knowledge guessing machine into a system that works with your specific business information.
How your documents become searchable.
For the AI to search your documents, those documents need to be converted into a format the system can work with. This is where vector embeddings come in. Think of it like creating a spatial map of meaning. Every piece of text in your documents gets converted into a set of mathematical coordinates that represent what that text is about.
Concepts that mean similar things end up near each other on this map, even if they use completely different words. "Revenue forecast" and "financial projections" land in the same neighborhood. "Employee onboarding checklist" and "new hire orientation guide" sit right next to each other. The map does not care about exact wording. It cares about meaning.
When someone asks a question, that question also gets converted into coordinates on the same map. The system then finds the document chunks closest to the question on the meaning map. This is how the AI finds relevant information even when the user phrases their question differently than the original document. You do not need to remember the exact words your company used. You just need to ask your question in plain language.
The RAG pipeline, step by step.
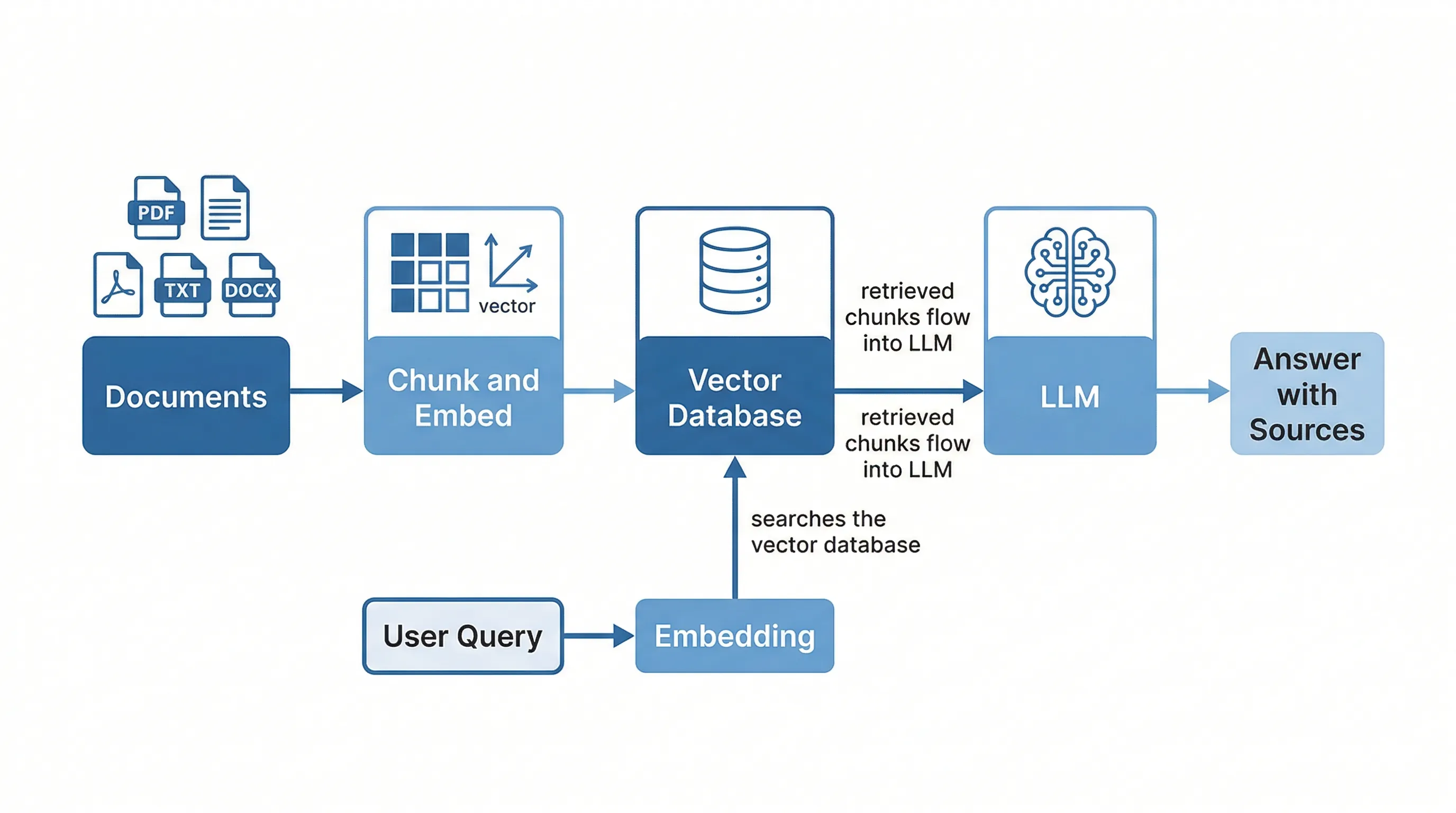
The process starts with your documents. PDFs, Word files, spreadsheets, web pages, internal wikis; whatever your team uses. These documents get split into smaller chunks, each covering one complete idea or section. The chunking matters more than most people realize. Split a document in the wrong place and you cut important context in half, which leads to incomplete or misleading answers later.
Each chunk then gets converted into a vector, its coordinates on the meaning map. These vectors are stored in a specialized database designed for fast similarity searches. This database can hold millions of document chunks and search through all of them in milliseconds. Once your documents are indexed, the system is ready to answer questions.
When someone asks a question, the question gets vectorized too. The system compares the question's coordinates against every chunk in the database and pulls back the closest matches. These matching chunks, usually three to ten of them, get passed to the AI along with the original question. The AI reads the provided chunks and writes an answer based specifically on that information.
The AI cites its sources, pointing back to the specific documents and sections it used. You can click through and verify. The whole process, from question to cited answer, takes seconds.
Where RAG systems go wrong.
RAG is powerful, but it is not foolproof. The most common failure is bad chunking. If your documents get split in the middle of an important paragraph or table, the AI receives incomplete information and gives an incomplete answer. Another frequent issue is the embedding model itself. If the model does not understand your industry's specialized terminology, it cannot find relevant documents when someone uses jargon in their question. A manufacturing company's technical vocabulary is very different from a law firm's, and generic embedding models may struggle with both.
Stale data is another common problem. Your team updates a policy document, but the vector database still contains the old version because nobody re-indexed it. The AI confidently gives an outdated answer with no indication that the source material has changed. And even with perfect retrieval, the AI can occasionally ignore the provided context and fall back on its general training data, generating answers that sound right but do not reflect your actual documents.
The good news: every one of these failures is fixable with proper engineering. Better chunking strategies, domain-specific embedding models, automated re-indexing, and careful prompt design all address these issues. The key insight is that most RAG failures are retrieval problems, not AI problems. If the system finds the right documents, the AI almost always gives a good answer. The hard part is making sure the right documents get found.
RAG vs. fine-tuning: which one do you need?
RAG and fine-tuning solve different problems. RAG is the better choice when your data changes frequently, you have multiple data sources, or you need source citations so people can verify answers. Fine-tuning is better when you need the AI to adopt a very specific tone or writing style, classify documents into rigid categories, or handle a narrow task at massive scale. For most businesses, RAG is the right starting point. It is faster to implement, easier to maintain, and does not require assembling training data. You can be up and running in weeks instead of months.
The two approaches can also be combined. You can fine-tune a model for your industry's language and then use RAG to give it access to your specific documents. But start with RAG first. It delivers the most value with the least effort. For more on choosing the right AI approach for your situation, see our guide to AI model sizing.
Real examples of RAG in action.
An HR team searches company policies and gets instant, accurate answers about parental leave eligibility instead of digging through a 200-page employee handbook. A sales rep queries product documentation mid-call and answers a prospect's technical question in seconds, without putting the client on hold or promising to follow up later. A legal team reviews vendor contracts against company standards in minutes instead of hours, flagging non-standard clauses automatically. A support team resolves tickets faster by instantly finding past solutions in the knowledge base, pulling up the exact steps that worked for the same issue three months ago.
The same approach applies to industry-specific workflows. An insurance brokerage can use RAG to search hundreds of pages of policy documents instantly, flagging coverage gaps during policy checking. A staffing agency can search its entire ATS database semantically, surfacing past candidates who match today's open reqs without relying on keyword filters.
What this means for your business.
If your team spends time searching for information that already exists somewhere in your files, RAG is the solution. It is one of the fastest, most cost-effective AI implementations available. You do not need to train a custom model. You do not need to restructure your data. You connect your existing documents to an AI that can search them intelligently, and your team gets answers in seconds instead of minutes or hours.
Steelhead builds RAG systems for operations teams across Calgary and Western Canada. Want to see if RAG fits your operations? Book a discovery call and we will show you what is possible.