Not all AI models are created equal.
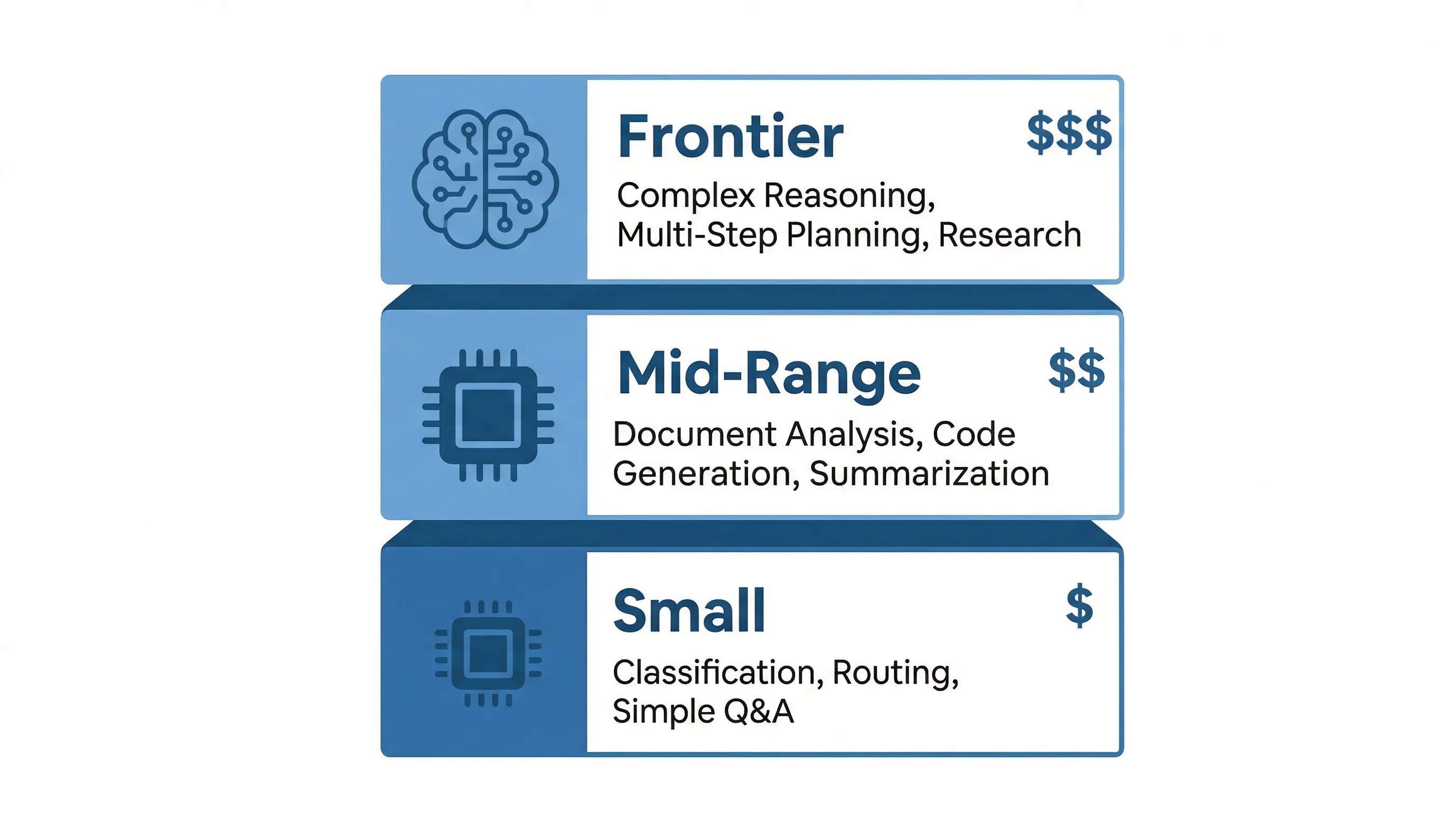
There are three broad tiers of AI models available today: small, mid-range, and frontier. Each tier is built for a different level of complexity, and each comes with a different price tag. The problem is that most businesses default to the biggest, most expensive model they can find, assuming that more power equals better results. That is rarely true.
Think of it this way: using a massive frontier model for a simple classification task is like hiring a senior aerospace engineer to sort spare change. Sure, they could do it. But it would be slow, expensive, and wildly overqualified for the job. The spare change does not need rocket science; it needs a coin sorter.
The right model depends entirely on what you are building. A customer support chatbot answering common questions has very different needs than a legal analysis tool parsing complex contracts. Matching the model to the task is one of the highest-impact decisions you can make when deploying AI across your business, and it is the one most companies get wrong.
Small models: fast, cheap, and surprisingly capable.
Small models have fewer than 10 billion parameters, and they cost roughly $0.10 to $0.40 per million tokens. A token is roughly three-quarters of a word. A typical paragraph of text is about 100 tokens. When AI providers quote pricing per million tokens, they are measuring how much text the model processes or generates. At these prices, small models are built for speed and efficiency. They handle classification, request routing, simple question-and-answer tasks, and structured data extraction without breaking a sweat. Response times typically come in under 200 milliseconds, and many of these models can run on local hardware without needing cloud infrastructure at all.
The results can be impressive. The background check company Checkr replaced a frontier model with a fine-tuned small model for one of their core workflows. The result: 30x faster processing, 5x lower cost, and higher accuracy on their specific task. When you have a well-defined, repeatable problem, like parsing resumes inside a staffing agency, a small model trained on your domain data can outperform a general-purpose giant.
Where small models fall short: complex reasoning, multi-step analysis, and tasks that require deep contextual understanding. If the job requires the model to hold a long conversation, synthesize information from dozens of sources, or make nuanced judgments, a small model will struggle. But for the thousands of simple, repetitive tasks that make up most business operations, they are more than enough.
Mid-range models: the workhorses.
Mid-range models sit in the 10 to 70 billion parameter range and cost roughly $0.30 to $15 per million tokens. They handle document analysis, code generation, report summarization, and workflow automation. They are the default choice for most business applications because they offer strong reasoning at a reasonable cost.
One of the biggest advantages of mid-range models is their context windows. Many now support up to one million tokens, which means they can process entire libraries of documents in a single request. That is a game-changer for businesses dealing with large volumes of contracts, reports, or compliance documents, like an insurance brokerage reviewing carrier policy wordings at renewal. You can feed the model everything it needs at once instead of breaking the work into small pieces.
Where mid-range models struggle: autonomous multi-step planning and tasks that require genuinely novel problem-solving. If you need a model to independently navigate a complex codebase, plan a multi-stage research project, or reason through ambiguous edge cases, you will hit the ceiling. For everything else, mid-range models deliver excellent results without the premium price tag.
Frontier models: when the stakes are high.
Frontier models have over 100 billion parameters and cost between $1.25 and $25 per million tokens. These are the models you reach for when the task demands complex reasoning, autonomous agent work, legal analysis, or financial modeling. They can work independently for hours, navigating codebases, planning multi-step tasks, and handling ambiguity that would trip up smaller models.
But using frontier models for simple tasks is a waste. There is a "generalist tax" that comes with routing everything through the most powerful option: you pay premium prices for commodity work. Companies that send all their AI traffic through a single frontier model typically overpay by 40% to 85% compared to companies that match models to tasks.
The key question is not "which model is the best?" but "which tasks actually need this level of capability?" For most businesses, the answer is a small fraction of their total volume. The rest can be handled by smaller, faster, cheaper models with no loss in quality.
The real answer: use more than one.
The smartest approach to AI model selection is not picking one model; it is using several. Think of it like a restaurant kitchen. Simple salads go to the prep cook. Standard dishes go to the line cooks. Complex souffles go to the executive chef. Every order gets handled by the right person for the job, and the kitchen runs efficiently because of it.
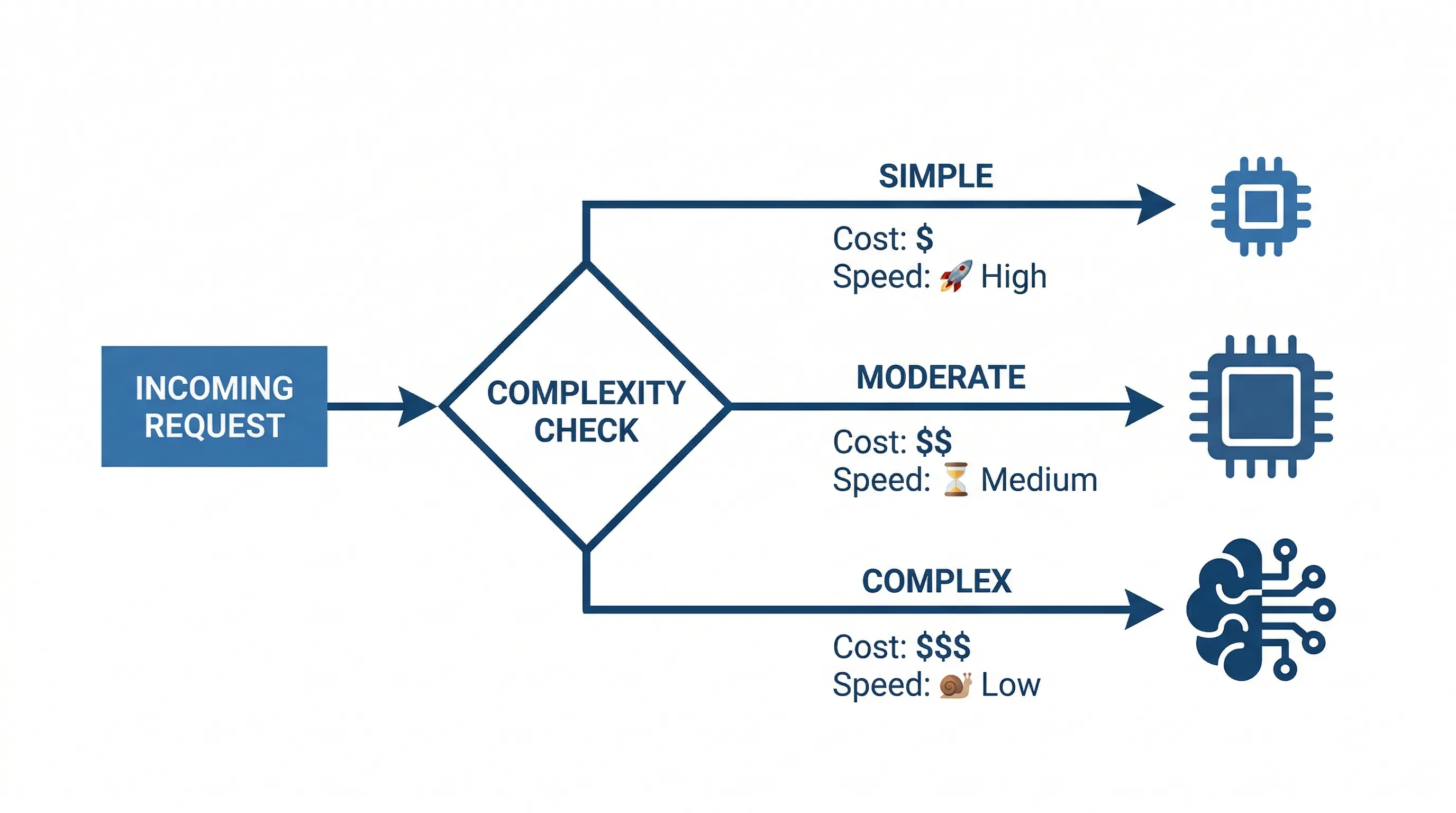
In AI, this is called intelligent model routing. A lightweight classifier reads each incoming request and determines its complexity. Simple requests, like categorizing a support ticket or extracting a date from an email, get routed to a small model. Moderately complex tasks, like summarizing a report, go to a mid-range model. Only the genuinely difficult work, the multi-step reasoning or nuanced analysis, goes to a frontier model.
Companies that implement intelligent routing save 40% to 85% on AI costs while maintaining quality where it matters. The savings come from not overpaying for simple tasks, and the quality holds because complex tasks still get the full power of a frontier model. It is the best of both worlds.
Fine-tuning vs. prompting: when to train your own.
Fine-tuning a small model on your domain data can outperform a frontier model for narrow, repetitive tasks. If your team processes thousands of similar documents every week, a fine-tuned model that has learned your specific terminology, formats, and decision criteria can be faster, cheaper, and more accurate than a general-purpose model. But fine-tuning requires clean training data, ongoing maintenance, and a task specific enough to justify the investment.
For most businesses, RAG (retrieval-augmented generation) is the better first step. RAG connects an AI model to your existing documents, databases, and knowledge bases without requiring you to train a custom model. The AI searches your data in real time and uses what it finds to generate accurate, grounded responses. It is faster to set up, easier to maintain, and works well for a wide range of tasks. If you are unfamiliar with the concept, start with our guide to RAG.
What this means for your business.
You do not need the most powerful model. You need the right model for the job. Start with the task you are trying to automate, then match the model to the complexity of that task. If you are processing thousands of simple requests, a small model will outperform and outprice a frontier model every time. If you need deep analysis on complex documents, that is where frontier capability pays for itself. And if you have a mix of both, which most businesses do, intelligent routing lets you get the best results at the lowest cost. A marketing agency automating monthly reporting does not need a massive model; a mid-range model handles the data aggregation while a frontier model writes the strategic narrative.
Steelhead works with operations teams across Calgary and Western Canada. Not sure which approach fits your operations? Book a discovery call and we will map it out together.